Unicorn story generation using the Semantic Kernel

Over the last couple of months, I have used the Semantic Kernel in different ways, usually as part of my exploration on how to use various LLMs together with the Dataverse MCP Server. I have blogged about how to use Semantic Kernel, and how it relates to the Microsoft.Extensions.AI libraries. I used the Semantic Kernel when I evaluated a number of large language models together with the Dataverse MCP Server, as part of my “Pizza Party” benchmark, which I describe in this blog post.
The future of Semantic Kernel
When I started looking into Semantic Kernel it seemed to be the most ‘enterprise-grade’ offering from Microsoft, when it came to more sophisticated AI agent orchestration. But it seems that things are happening internally at Microsoft that might change this in the future. A while back I stumbled across a video from Rasmus Wulff Jensen where he talked about the future of Semantic Kernel - how it is now entering “maintenance mode” and that the Semantic Kernel team is merging with the Autogen team. The goal seems to be to introduce a new agent orchestration framework that will replace Semantic Kernel and Autogen. I started attending the Semantic Kernel team’s weekly “Office Hours” calls to learn more. This was a great experience, the team was super-helpful and the TL;DR regarding the future of Semantic Kernel seems to be:
- A new framework will be released, probably this year.
- The name of the framework is currently unknown.
- It should be considered a “Semantic Kernel 2.0”, and there will be clear migration paths for customers that are using SK today.
So, that sounds pretty good for existing users of SK, and there seems to be exciting things ahead when Microsoft launches the new “Agent Orchestration Framework” (or whatever it will be called…).
The SK team also shared a lot of other interesting information, for example that MCP support for the C# SDK has been available a while, although the documentation has not been updated. They pointed to some useful sample code in GitHub.
Another interesting thing was the support for the OpenAI Responses API in SK, through the Responses Agent, as is discussed here. There are some code samples available here, and I thought it would be fun to test how Semantic Kernel can be used to call the Responses API…
This led me down a rabbit hole exploring experimental libraries, running Transformers locally, creating Dockerfiles, forking of both the Semantic Kernel and the C# Open AI SDK and in the end - short stories of unicorns and rainbows… 🦄🌈
The OpenAI Responses API and Semantic Kernel
I have wanted to look into the OpenAI Responses API for a while. OpenAI describes it as “…the most advanced interface for generating model responses” and it has a lot of cool features, for example:
- You don’t have to pass all previous messages with every call (like you have to do with the Chat Completions API), the service keeps track of the conversations for you.
- It has built-in support for file search, web search, computer use and code execution. So there are some cool things that the LLM can do internally, without having to rely on external MCP Servers for these things.
And as mentioned above, Semantic Kernel supports the Responses API, so let’s try it out to call the OpenAI Responses API using the Semantic Kernel, and use the Web Search tool to search for information about unicorns.
In the example below I have added a Http-handler so I can output the request that is actually sent to the OpenAI API. Since the OpenAIResponseClient is experimental, we need to add some pragma directives to suppress the warnings.
var httpClient = new HttpClient(new LoggingHandler(new HttpClientHandler()));
var transport = new HttpClientPipelineTransport(httpClient);
#pragma warning disable OPENAI001
OpenAIResponseClient client = new OpenAIResponseClient("gpt-5-mini", new ApiKeyCredential("..."), new OpenAI.OpenAIClientOptions()
{
Transport = transport
});
OpenAIResponseAgent agent = new(client)
{
StoreEnabled = false,
};
// ResponseCreationOptions allows you to specify tools for the agent.
ResponseCreationOptions creationOptions = new();
creationOptions.Tools.Add(ResponseTool.CreateWebSearchTool());
OpenAIResponseAgentInvokeOptions invokeOptions = new()
{
ResponseCreationOptions = creationOptions,
};
// Invoke the agent and output the response
var responseItems = agent.InvokeStreamingAsync("Do a web search for information about unicorns (the mythnical creature), summarize in three sentences.", options: invokeOptions);
...
public sealed class LoggingHandler : DelegatingHandler
{
public LoggingHandler(HttpMessageHandler inner) : base(inner) { }
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage req, CancellationToken ct)
{
// Log URL
Console.WriteLine($"Request URL: {req.RequestUri}");
// Log headers
Console.WriteLine("Request Headers:");
foreach (var header in req.Headers)
{
Console.WriteLine($"{header.Key}: {string.Join(", ", header.Value)}");
}
if (req.Content != null)
{
foreach (var header in req.Content.Headers)
{
Console.WriteLine($"{header.Key}: {string.Join(", ", header.Value)}");
}
// Log content
var content = await req.Content.ReadAsStringAsync();
Console.WriteLine("Request Content:");
Console.WriteLine(content);
}
else
{
Console.WriteLine("No request content.");
}
return await base.SendAsync(req, ct);
}
}
The above results in the following request:
Request URL: https://api.openai.com/v1/responses
Request Headers:
Accept: application/json, text/event-stream
User-Agent: OpenAI/2.3.0, (.NET 9.0.8; Microsoft Windows 10.0.26100)
Authorization: Bearer ...
Content-Type: application/json
Request Content:
{"instructions":"","model":"gpt-5-mini","input":[{"type":"message","role":"user","content":[{"type":"input_text","text":"Do a web search for information about unicorns (the mythnical creature), summarize in three sentences."}]}],"stream":true,"user":"UnnamedAgent","store":false,"tools":[{"type":"web_search_preview"}]}
And the response:
The unicorn is a mythological creature—usually depicted as a horse- or goat‑like animal with a single spiraling horn—whose stories appear in ancient cultures from the Indus Valley and Mesopotamia through classical Greece, China, and medieval Europe. ([britannica.com](https://www.britannica.com/topic/unicorn?utm_source=openai), [worldhistory.org](https://www.worldhistory.org/article/1629/the-unicorn-myth/?utm_source=openai))
...
By the Middle Ages the unicorn was widely used as an allegory of purity and Christ in bestiaries and art (notably The Hunt of the Unicorn tapestries), and it survives today as a pervasive cultural symbol in literature, art, and popular media. ([britannica.com](https://www.britannica.com/topic/unicorn?utm_source=openai), [worldhistory.org](https://www.worldhistory.org/article/1629/the-unicorn-myth/?utm_source=openai))
This works well, no problem at all. It should be noted that the Semantic Kernel uses the OpenAI C# SDK under the hood, so SK is closely tied to that library. This will be of importance as we continue exploring.
It should be noted that even for this simple request - consisting of a single question to the AI - the request is serialized to this somewhat complex format:
"input":[{"type":"message","role":"user","content":[{"type":"input_text","text":"Do a web search for information about unicorns (the mythnical creature), summarize in three sentences."}]}]
If one reads the Responses API documentation, it is clear that there is a simplified format, where the input is a simple string instead of the more complex structure above:
{
"model": "gpt-4.1",
"input": "Tell me a three sentence bedtime story about a unicorn."
}
This simplified format can also be used for calls that contains several messages:
"input": [
{
"role": "developer",
"content": "Talk like a pirate."
},
{
"role": "user",
"content": "Are semicolons optional in JavaScript?"
}
]
So which format is correct? I tried to find a formal specification of the input formats that can be used for the Responses API, but I couldn’t find it (if you can, let me know!) My assumption is that both the simple and the more complex formats are perfectly fine, and should be supported by all endpoints that supports the Responses API. But as it turns out, that is not the case…
Using Semantic Kernel and the Responses API locally
If you have read my blog and my posts on LinkedIn, you know that I like to run LLMs locally. I have blogged about Foundry Local and experimented with using the open weights OpenAI gpt-oss models together with the Dataverse MCP Server. So, of course I had to try if it was possible to call the gpt-oss models using the Responses API somehow. These models are compatible with the Responses API, so it should be possible to do, right?
The Hugging Face Transformers framework has experimental support for the Responses API and there even is an OpenAI cookbook that explains how to run gpt-oss locally using Transformers! So let’s try it out!
Setting up the Hugging Face Transformers library
This is really not my area of expertise, and it took a lot of tinkering - but eventually I was able to create a Docker image that runs the Transformers library and that can run the openai/gpt-oss-20b model and serve up a Responses API compatible endpoint at http://localhost:8000/v1/responses! The repo that contains the Dockerfile and docker-compose.yml can be found here.
If we call it using Postman we get a gazillion streaming chunks back:
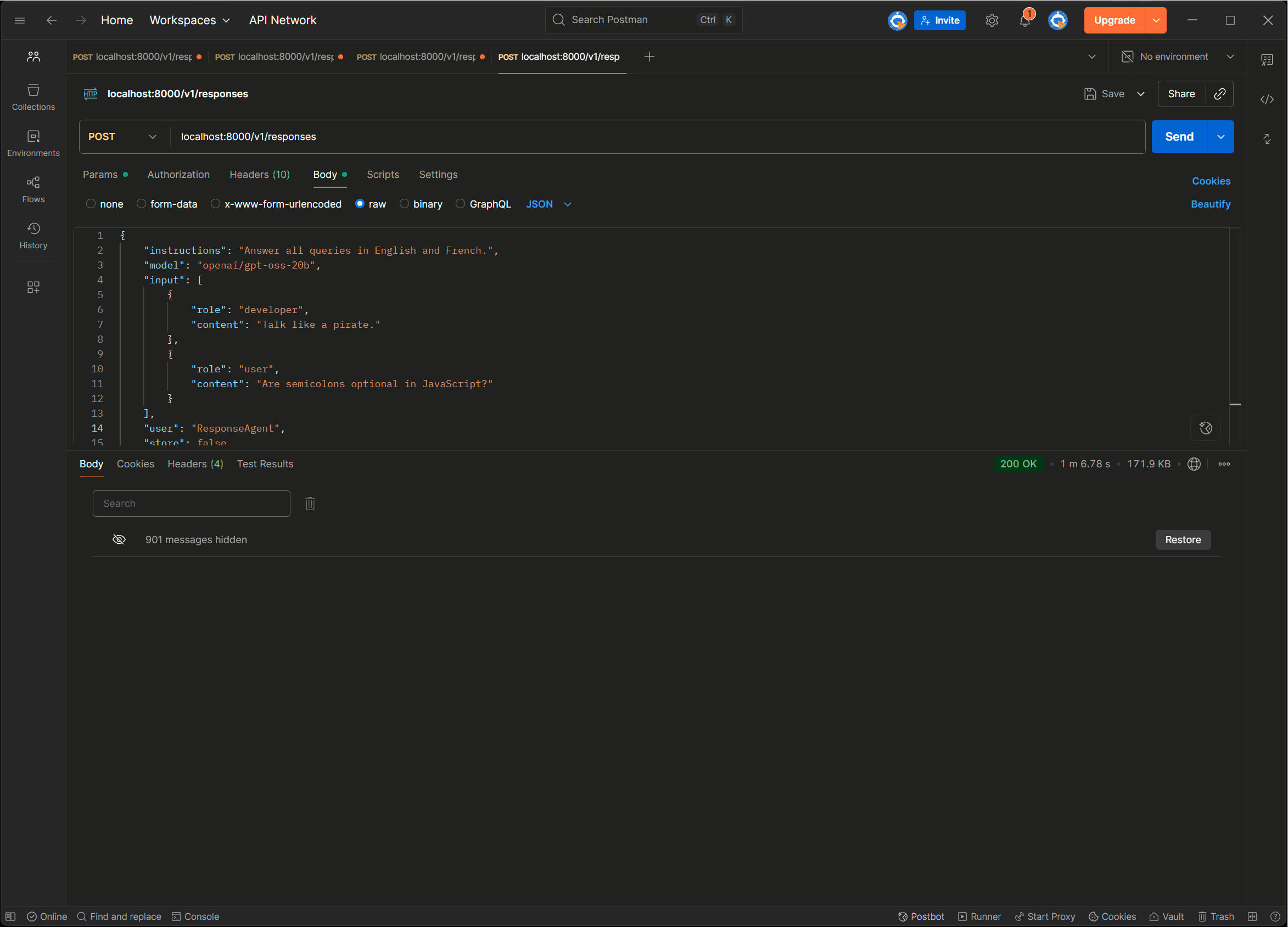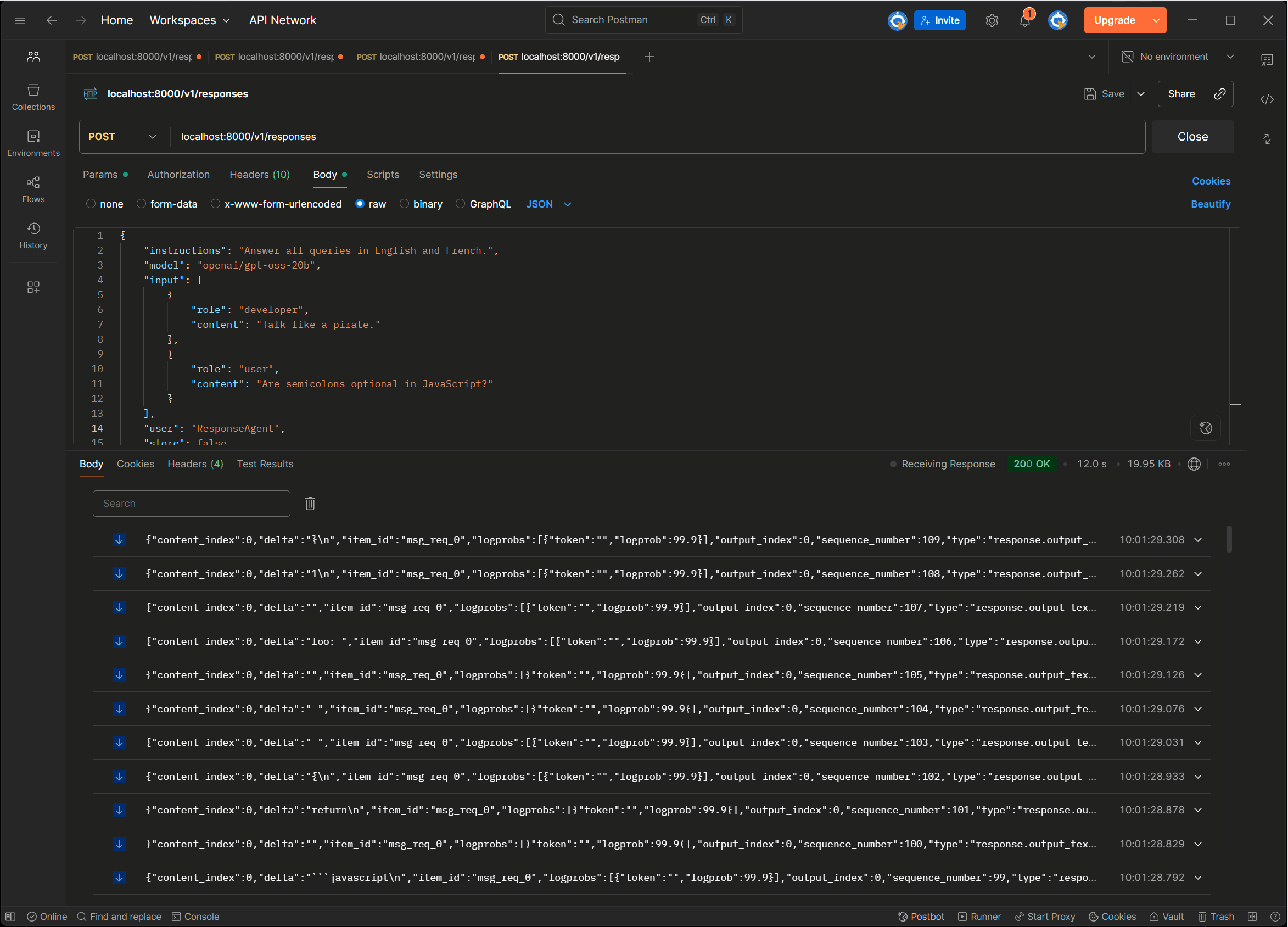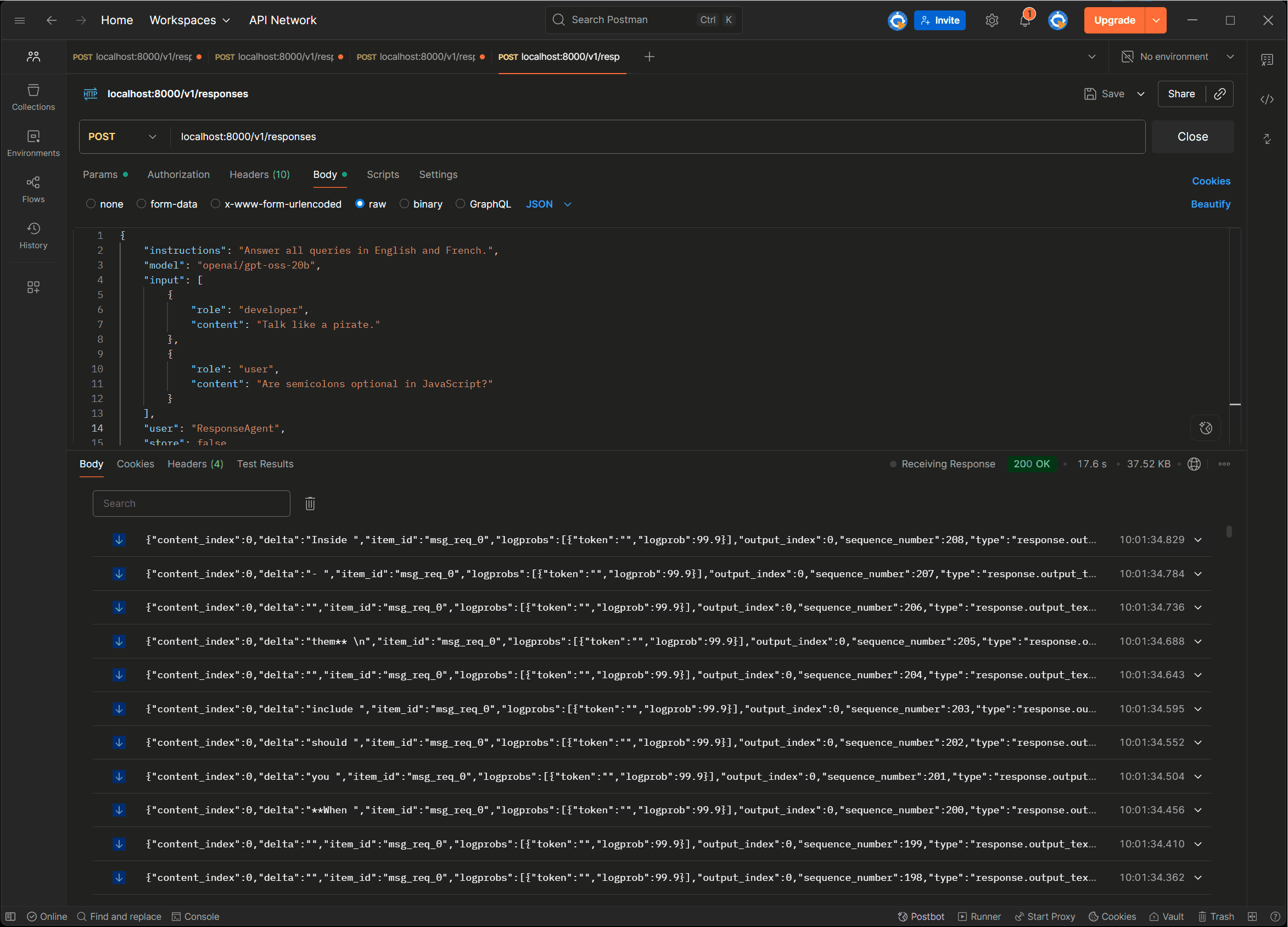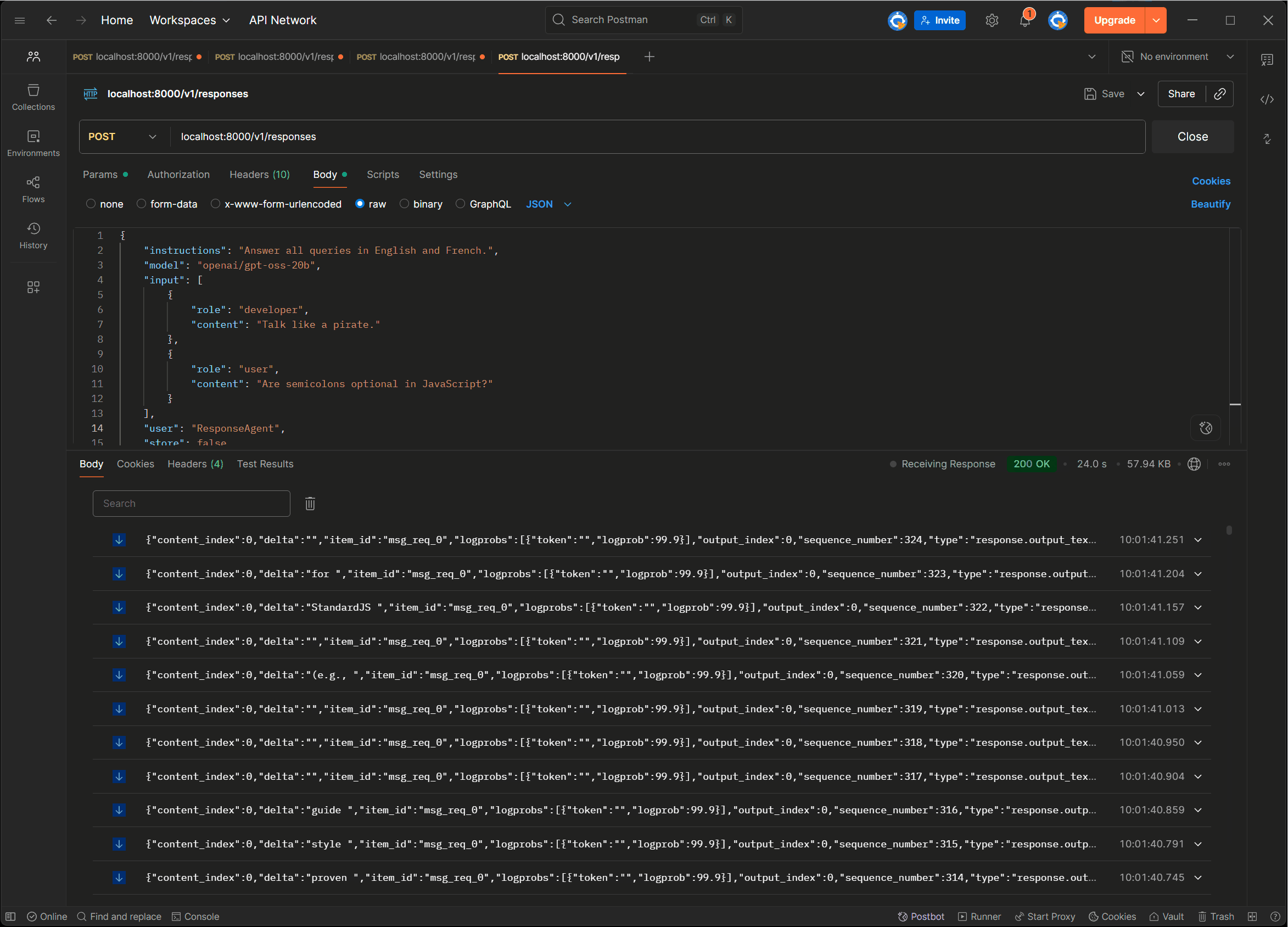
So far, so good. Now let’s try the Semantic Kernel, and see if it can talk to the API:
var httpClient = new HttpClient(new LoggingHandler(new HttpClientHandler()));
var transport = new HttpClientPipelineTransport(httpClient);
#pragma warning disable OPENAI001
OpenAIResponseClient client = new OpenAIResponseClient("openai/gpt-oss-20b", new ApiKeyCredential("No API key needed!"), new OpenAI.OpenAIClientOptions()
{
Endpoint = new Uri("http://localhost:8000/v1"),
Transport = transport
});
OpenAIResponseAgent agent = new(client);
// Invoke the agent and output the response
var responseItems = agent.InvokeStreamingAsync("Tell me a joke!");
Ouch! This returns an internal server error, and if we review the Transformers logs we can see that something has gone wrong:
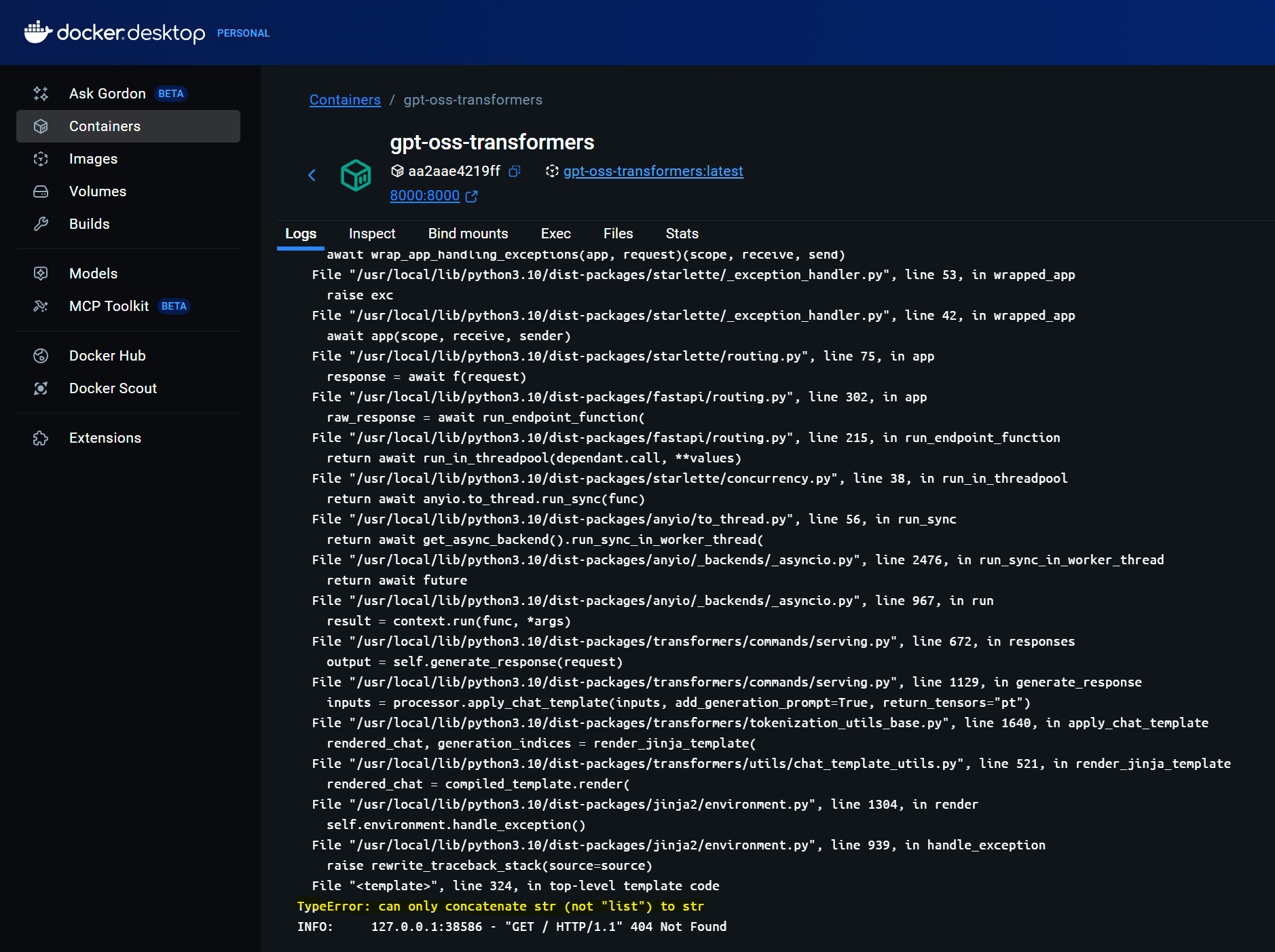 If we inspect the request that was sent to the endpoint we can see that it has the “complex” format:
If we inspect the request that was sent to the endpoint we can see that it has the “complex” format:
Request URL: http://localhost:8000/v1/responses
Request Headers:
Accept: application/json, text/event-stream
User-Agent: OpenAI/2.3.0, (.NET 9.0.8; Microsoft Windows 10.0.26100)
Authorization: Bearer No API key needed!
Content-Type: application/json
Request Content:
{"instructions":"","model":"openai/gpt-oss-20b","input":[{"type":"message","role":"user","content":[{"type":"input_text","text":"Tell me a joke!"}]}],"stream":true,"user":"UnnamedAgent","store":false}
Unfortunately, the Transformers Responses API doesn’t like this format. As we saw before, it works fine with the simpler format - but for some reason this doesn’t work. Probably because it is experimental. I logged an issue, so we’ll have to see what happens. UPDATE: 2 hours after raising the issue, there is already a PR with a fix - these guys are fast!
So what should we do?
Forking the C# OpenAI SDK and Semantic Kernel
I really wanted to make this work, and I thought that my only option was to make sure that the request sent from Semantic Kernel was in the simplified format that Transformers (currently) supports. So, I forked the OpenAI .NET API library and tried to tweak it to make sure that it works in my scenario.
It turns out that OpenAIResponse.Serialization.cs is responsible for serializing the input, and could be tweaked to emit the simplified format instead. Note that this is not a bug in the serializer - it has been automatically generated based on the OpenAI API spec, so it works as it should.
When this was fixed it still didn’t work because of some strangeness in the format of the response that was returned from Transformers, which meant that I had to fork Semantic Kernel also, and do a tweak there as well.
After all this tweaking it finally works - a joke has been generated using a local gpt-oss-20b model, running on the Hugging Face Transformer library and using the Responses API. Great success!
➡️ POST http://localhost:8000/v1/responses
Accept: application/json,text/event-stream
User-Agent: OpenAI/2.3.0,(.NET 8.0.19; Microsoft Windows 10.0.26100)
Authorization: [MASKED]
{"user":"UnnamedAgent","model":"openai/gpt-oss-20b","instructions":"","input":[
{"role":"user","content":"Tell me a joke!"}],"store":false,"stream":true}
⬅️ 200 OK
here’s one for you:
Why did the scarecrow win an award?
Because he was outstanding in his field! 🌾😄
Generating short stories about Unicorns using Semantic Kernel, Transformers and Responses API
So, at the depth of the Responses API rabbit hole, it was finally possible to ask the AI to create some short stories about unicorns, some emojis and some nice, bright colors. A repo containing this demo, as well as the tweaked forks of the C# OpenAI SDK and Semantic Kernel can be found here. Here’s the result:
It feels like I probably spent way too much time to be able to ask the AI about unicorns, but at least I learned some things about Docker, Transformers and got a chance to dive deeply into the SK and OpenAI .NET codebases. 😄