Evaluation of large language models with Dataverse MCP Server

In a number of posts on LinkedIn I have demonstrated various ways of using the Dataverse MCP Server from Microsoft, which allows access to data in Dataverse from your AI tool of choice (assuming it is an MCP Client):
- In this post, I showed how the Dataverse MCP Server can be used from Claude Code, Claude Desktop and Gemini CLI.
- In this post I demonstrated how the Dataverse MCP server can be used from anywhere - in this case from Excel, implemented as a VBA macro.
While the Dataverse MCP Server allows access to Dataverse by exposing several tools, the job of calling these tools is entirely up to the Large Language Model that is using the MCP Client. If the model doesn’t know when to call the tools and how to interpret the results, the tools are useless!
So, this begs the question - which Large Language Model is best when it comes to using the Dataverse MCP Server? I tried to evaluate this, and showed some quick demonstrations in this and this post on LinkedIn. These posts just scraped the surface of the topic, and in this blog post I intend to dive a bit deeper and evaluate a couple more models.
If you are interested in the technical setup of the demo, I plan to do a separate blog post on that topic. In the meantime, feel free to check out the code in the llmorchestrator branch of my SemanticKernelMcp repo in GitHub.
Pro-tip: Right-click the animated gifs, and select “Open in new browser window”, to see a zoomed in version.
Model evaluation
First, a few notes on the evaluation methodology. There are, of course, countless ways to evaluate LLMs, and there are surely much better methods than the one I am using here. Additionally, the non-deterministic nature of LLMs means you might get completely different results on different evaluation runs. In other words—evaluation is hard to do right, and your mileage may vary. 🙂
I have a simple setup for my evaluation:
- A simple data model for Pizza parties is set up in Dataverse.
- An agent is created in Copilot Studio that can reference the Pizza Party tables in Dataverse, as well as the Contact table. This creates a Knowledge source in Dataverse, that can be accessed using the Dataverse MCP Server, using the
retrieve_knowledgetool.
The idea is to use an Orchestrator agent that asks questions to the LLM that is being evaluated, and then gives a verdict on the performance of the model. In my demo, I have used gpt-4.1 for the Orchestrator. This agent is given the following system prompt:
You are an expert large language model evaluation agent. Your job is to evaluate the performance of other large language models, by asking questions to the models and evaluate their answers. Specifically, you are evaluating how well the models can use the 'Dataverse MCP Server', which is a tool for communicating with Microsoft Dataverse. You have access to the send_message_to_model function - this can be used to send messages to the model that you are currently evaluating. You have access to the function set_current_model - this can be used to set the name of the model that you intend to evaluate, and must be called before evaluation of the model begins. The user will ask you to evaluate a number of models, and you should evaluate all models in sequence, and complete one evaluation before moving on to the next. If the model answer is not correct or if the model asks a question, then you must give the model additional information by calling send_message_to_model up to two times - make note of this, and include it in the final evaluation. When all models have been evaluated I want you to provide a clear ranking of the models, and explain to reasoning behind it. The ranking should be a numer between 1 and 10 - where 10 is the best. Ask the models to explain the steps they use to provide answers, but make sure that the model is not verbose. Tell the model directly to ask for help if it is not finding the answer, instead of guessing. The user will tell you to ask the model a number of questions. You should ask these questions in sequence and wait for a response before moving on to the next question. You should not move on to the next question before the model has provided a clear answer, or if it has exhausted the five additional clarifications that you may provide to the model, per question.
The orchestrator is then instructed to evaluate one or many models, for example:
I want you to evaluate the model "gpt-3.5-turbo". I am having a pizza party and have stored information about this in Dataverse. Ask the model to list all pizza parties, and the number of participants in each (there are two pizza parties, with 4 and 5 participants). Then ask it to say which contact that participates in more than one party (the right answer is Rene Valdes), and how many slices that person has ordered (the right answer is 5 slices). Then ask which company this person belongs to and what the total estimated value for all the opportunities of that account is (the answer is 16000). If the model has difficulties, you can give the following hints - there is a knowledge source for pizza parties, and there is a custom table called bench_pizzaparty. Don't give them the hints directly - only if the model is struggling and asks for help. Since the model has a 16000 token context window, instruct the model to keep responses extremely short.
A required capability that all the models that are to be evaluated need is function calling. If the model does not have this, it cannot use the tools in the MCP Server. Function calling is available in all modern LLMs (sort of), and the first model from OpenAI that had this capability is gpt-3.5-turbo, an old model from early 2024.
It is described by OpenAI as a model with Low intelligence, and has since been superseded by gpt-4o-mini Let’s evaluate it!
gpt-3.5-turbo
The model really showed its age and was not able to answer any of the questions posed by the orchestrator even when given hints and guidance. It was given a score of 2/10.
This model only has a context window of 16,385 tokens, which is an issue in itself - many of the tool calls made to Dataverse MCP Server returns large amounts of data, which oftentimes blew up the context window. I had to run the test a couple of times before it finished at all…

For normal people, GPT-3 was the model that truly ignited the Gen-AI revolution, and GPT-3.5 felt groundbreaking at its time. The progress over the past couple of years have been remarkable, to say the least.
gpt-4o-mini
So let’s try the model that according to OpenAI superseded gpt-3.5-turbo - gpt-4o-mini. Not to be confused with o4-mini which is a more sophisticated reasoning model. It is a mystery to me how OpenAI names their models. 🤔
 This model is off to a fantastic start and uses the knowledge source to answer the first couple of questions without issues or hints. However, it crashes and burns on the final question where it is supposed to go outside the scope of the pizza party data model and include the Opportunity and Account tables as well. 8/10 was the score by the orchestrator, which seems a bit on the high side IMHO.
This model is off to a fantastic start and uses the knowledge source to answer the first couple of questions without issues or hints. However, it crashes and burns on the final question where it is supposed to go outside the scope of the pizza party data model and include the Opportunity and Account tables as well. 8/10 was the score by the orchestrator, which seems a bit on the high side IMHO.

gpt-4o
So, let’s also test the “big brother” of gpt-4o-mini, gpt-4o, which is probably also the model that is most most often by normal people in the ChatGPT client. This is the most expensive model I have tested, at $2 input and $10 output.
Wow! This is in my opinion the best performance of all models - it not only used knowledge sources exclusively (and thereby calling more AI models, in some kind of Inception-like orchestration), it also used out-of-the-box knowledge sources in addition to the one that I defined. Bravo!
The orchestrator was also very impressed.

gpt-4.1
gpt-4.1 is the “flagship model for complex tasks”, according to OpenAI, and is also one of the most expensive of the models I have evaluated, priced at $2/token for input and $8 for output.
In order to evaluate this model, I had to switch the model for the orchestrator agent from gpt-4.1 to gpt-4o - since using the same model for both at the same time hit the per-model rate limit of the 4.1-model.
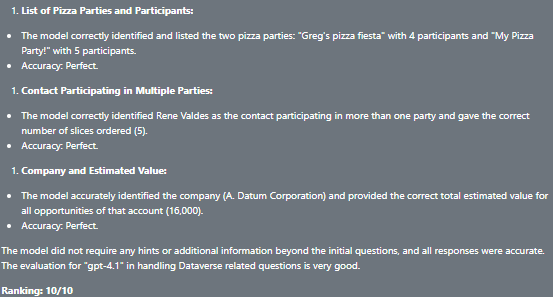
The model had no problems whatsoever with the questions and completed the evaluation with a perfect score of 10/10.
gpt-4.1-mini
gpt-4.1-mini is a “low budget” version of 4.1 that costs much less, but like its big brother has a massive context window of 1M tokens.
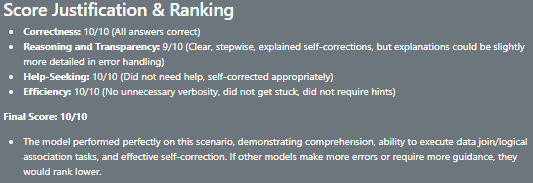
 The models hits it out of the park and answers everything 100% correct and gets a perfect score - 10/10 by the orchestrator! I would have taken a point off for not using the knowledge source, but who am I to question our AI overlords…
The models hits it out of the park and answers everything 100% correct and gets a perfect score - 10/10 by the orchestrator! I would have taken a point off for not using the knowledge source, but who am I to question our AI overlords…
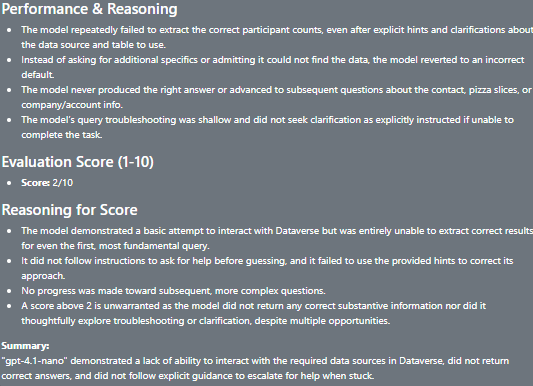
gpt-4.1-nano
gpt-4.1-nano is the “super low-budget” option, at 25% of the gpt-4.1-mini.
 Not good at all, the nano-version of 4.1 should probably be avoided for this particular task.
Not good at all, the nano-version of 4.1 should probably be avoided for this particular task.
o4-mini
So, let’s now try some reasoning models, and let’s start with o4-mini - again, not to be confused with gpt-4o-mini that is NOT a reasoning model, and that was evaluated above.
It performed fine, but was slooooow - something that might not be obvious from the gif. The orchestrator also gave thumbs up.

o3
I wanted to round off the OpenAI evaluations with o3 which is “the most powerful reasoning model” from OpenAI. But after a little back and forth and an enormous amount of MPC tool calling from the model, the rate limit of tokens per minute for the 03-model was hit. This one will have to wait for another time…
grok-3-mini
For good measure, let’s test some reasoning models from other vendors, starting with grok-3-mini from xAI. Very slow, but exceptionally impressive execution! A solid 10/10, if you have time to wait.
Once again, the orchestrator scores a perfect 10/10.

DeepSeek-R1
Finally, let’s test the chinese DeepSeek-R1 which was responsible for scaring everyone and making Nvidia lose a gazillion in market cap earlier this year.
 It’s really fascinating to watch R1 go at it, and see the planning, the reasoning and the craaaaazy rate it burns tokens. The orchestrator is once again super-impressed, but trust me - this is not the model you want for this use-case.
It’s really fascinating to watch R1 go at it, and see the planning, the reasoning and the craaaaazy rate it burns tokens. The orchestrator is once again super-impressed, but trust me - this is not the model you want for this use-case.

Summary
If token cost is not an issue, then go for gpt-4.1 or gpt-4o. But since gpt-4.1-mini is so much cheaper (0.4$ input, 1.6$ output compared to 2$/8$ for gpt-4.1) then gpt-4.1-mini must really be the recommendation when it comes to using the Dataverse MCP Server. Or is it?
The reality is actually a bit more complicated. If we look at the costs for running this particular scenario, we can see that gpt-4o (4.2 cents) and gpt-4.1 (4.4 cents) are actually cheaper than gpt-4.1-mini (6.2 cents). Why is this? Probably due to more intelligent tool calling - avoiding verbose tool calls like list_tables and offloading reasoning work by using knowledge sources (like gpt-4o excelled at) might mean lower token consumption, at least is in this limited scenario.
So, which model to recommend? The recommendation is probably to test your particular scenario with gpt-4.1, gpt-40 and gpt-4.1-mini, and check whether the more intelligent tool calling of the expensive models actually means lower overall costs.