Foundry Local, the new OpenAI models and the Harmony response format
About a week ago (prior to the release of the highly anticipated GPT-5 model), OpenAI released its first open weights model since GPT-2, the gpt-oss-20b and gpt-oss-120b models.
I tried out gpt-oss-20b (the 20 billion parameter model) using LM Studio, and recorded a video showing how well the model handles tool-calling, using the Dataverse MCP Server. It turned out to work very well - at least in comparison to other models in my Pizza Party benchmark.
A week after its release, the reviews of the OpenAI OSS models are somewhat mixed, but mostly positive. My overall feeling is that the model (I have only done very limited tests of the 120b model) is very capable, especially when it comes to tool calling - and it is very fast!
A couple of days following the release, Microsoft announced that the gpt-oss models were available to run on Foundry Local, an on‑device AI inference solution currently in preview.
I have wanted to test Foundry Local for a while, and I thought it would be interesting to see how well it could host the OpenAI models.
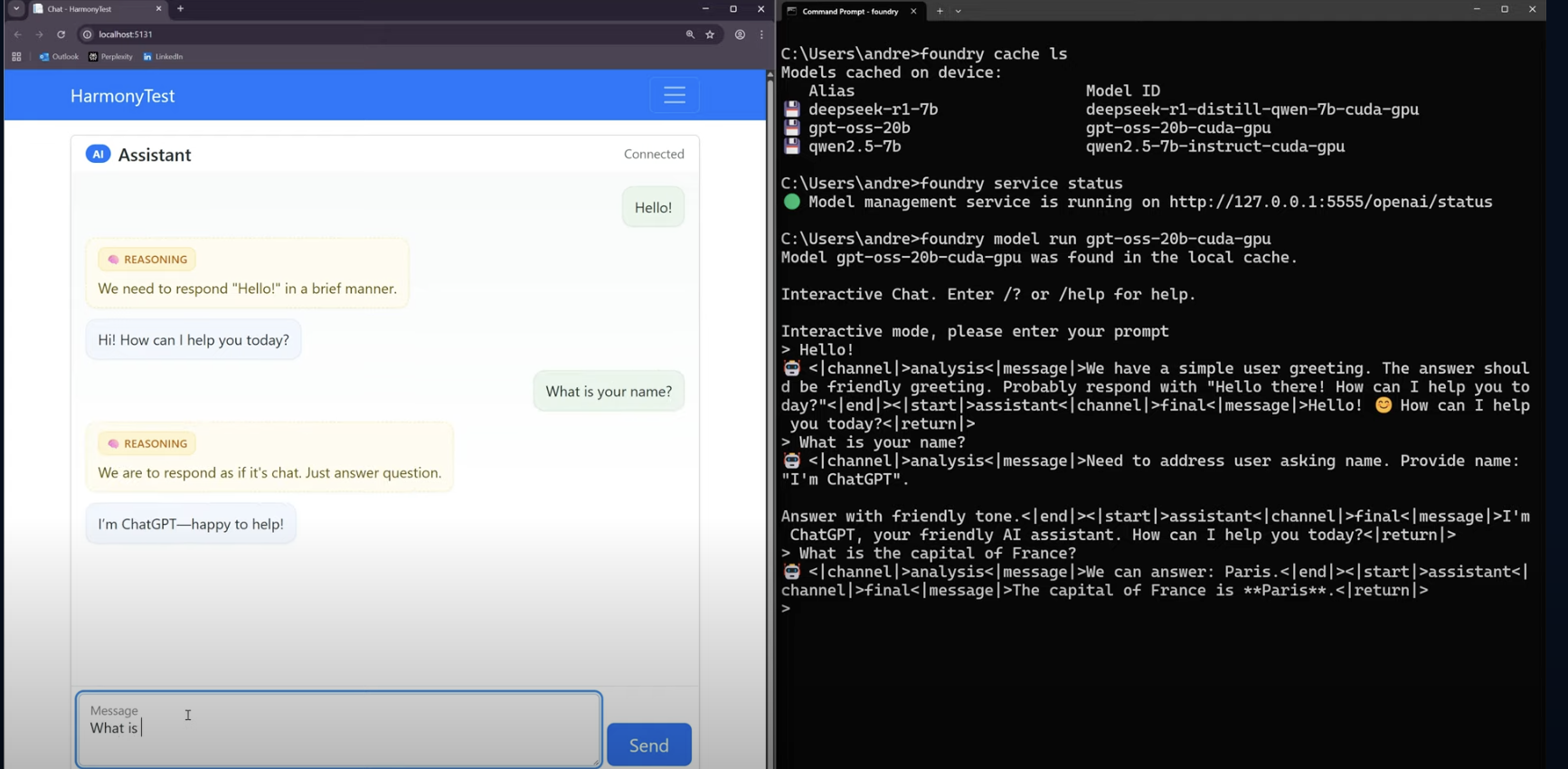
Foundry Local provides an OpenAI compatible REST API that lets you use the models from any AI chat clients that can use an OpenAI API endpoint. After testing out a couple of such clients, it became clear that none of the clients (that I tried) supported the new Harmony response format that the models use. The format looks like this:

I wanted a client that could show the model’s “train of thought” in a nice way, without all the Harmony tags. So, I decided to vibe-code my own client (using GPT-5, of course), the result is shown in the video below, and the code can be found in this repo in GitHub.
I used Microsoft.Extensions.AI in the demo, and one gotcha that I encountered was that I had to increase the MaxOutputTokens value, otherwise the response was cut off - I guess that the default value isn’t very high.