Running Foundry Local Models from Copilot Studio

In a recent LinkedIn-post and a YouTube video I demonstrated how you can use local models running on your own computer from Copilot Studio. This blog post details how this was accomplished technically. The code for this example can be found in this GitHub repo.
Creating the Copilot Studio agent
We start by creating an agent that should act as a pure proxy for calls to a local LLM. We tell the Copilot Studio agent that it has access to two topics:
-
RemoteLLMAdmin which should be invoked every time the user wants to perform various administrative tasks, such as listing the available models in Foundry Local, or loading models.
-
RemoteLLMChatCompletion that should be invoked in all other cases. This topic is responsible for requesting chat completions from the local model.
This is the full instruction to the Copilot Studio model:
You are an agent that sends all requests from the user to a remote large language model that is running in Azure Foundry Local and returns the responses from this model without modifying them. You should always call the "RemoteLLMAdmin" topic if the user wants to perform administrative operations on Foundry Local, for example:
- List the available models in the Foundry Local catalog.
- List the models that are currently loaded in Foundry Local.
Otherwise, you should always call the "RemoteLLMChatCompletion" topic. You should NEVER look in any knowledge sources - there can be no exceptions to this.
In Copilot Studio:
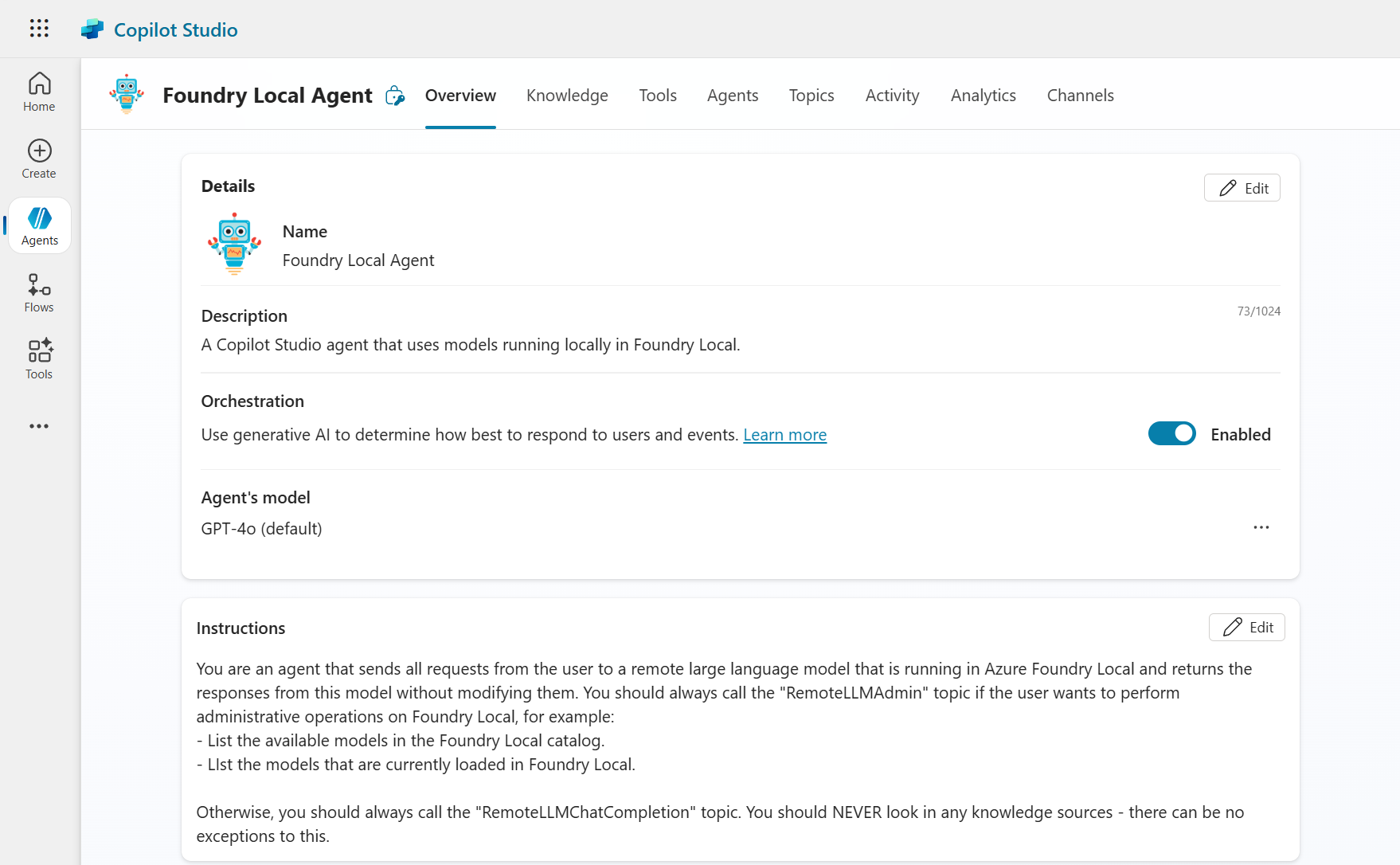
Since we want the Copilot Studio to be a mere proxy for calls to the local LLM, we also disable its ability to search the web:

The RemoteLLMAdmin and RemoteLLMChatCompletion topics
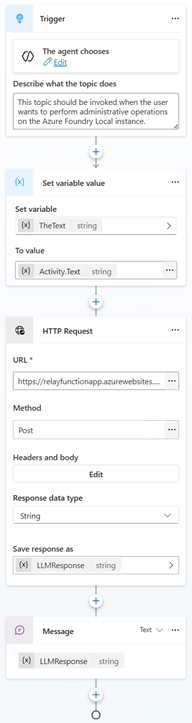
The RemoteLLMAdmin topic should be called by Copilot Studio whenever the user wants to perform administrative tasks in Foundry Local.
- The variable
TheTextis set to the input textActivity.Text, which will be used to add the text dynamically in the HTTP request to the Azure Function. - The input message is passed as an HTTP Request to an Azure Function, which then passes the message on to the local model using Azure Relay (see below).
- The response from the local LLM is then passed back to the user.
The HTTP request body is set to content type JSON, and we then pass a simple JSON structure that tells the orchestrator on my local computer to pass this request to the orchestrator LLM, and not to the Foundry Local model.
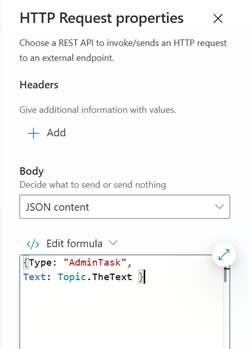
The RemoteLLMChatCompletion topic is identical, except the instruction and the JSON structure that is passed to the Azure Function:
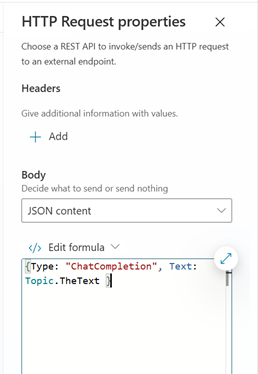
Why two different Copilot Studio topics?
The solution uses both a Foundry Local model and a model running in LM Studio - for a specific reason: Foundry Local doesn’t currently support OpenAI-style tool/function calling when using its OpenAI-compatible endpoint.
According to this thread, Foundry Local’s API is only compatible with “basic chat completion, embedding, and completion endpoints, not function calling.” This will of course change in the future, as Foundry Local evolves.
We need support for tool calling to make it possible for the agent do stuff locally, for example interacting with the local computer and calling the Foundry Local SDK to load models, etc - so admin tasks are routed by the RemoteLLMAdmin topic to a model served by LM Studio (in this case, to the model unsloth/qwen3-30b-a3b-instruct-2507), which supports tool calling. Regular chat completion requests are routed to Foundry Local.
The Azure Function - receiving the prompt from Copilot Studio
Both topics send HTTP Post requests to an Function App - RelayClient - running in Azure. The Function has a simple job - to pass on the HTTP request to my local machine using Azure Relay.
Azure Relay - passing the prompt to the local machine
Azure Relay is a nifty technology for creating Hybrid Connections between the cloud and a local machine, bypassing firewalls, etc. In addition to the RelayClient described above, a Relay Server - LocalRelayServer - is created, a console application that runs continuously on my local machine and receives HTTP requests passed on from the Azure Function.
The Azure Relay client and server are based on the .NET HTTP sample found in the Azure Relay documentation. The docs describe the steps necessary to configure an Azure Relay Hybrid connection.
It might be interesting to know what an Azure Relay resource costs - this information is found on the Azure Service Bus pricing page:

So, the pricing for a listener is around 9.7$ per month, which is pretty cheap.
LocalRelayServer - the local LLM router
The LocalRelayServer has dual purposes:
- To receive the HTTP messages that are relayed from Copilot Studio.
- To route the messages to the correct LLM.
The router inspects the JSON structure, and propagates the call to the correct LLM client:
public static async Task RunAsync(IConfiguration configuration)
{
var relayNamespace = configuration["AzureRelay:RelayNamespace"];
var connectionName = configuration["AzureRelay:ConnectionName"];
var keyName = configuration["AzureRelay:KeyName"];
var key = configuration["AzureRelay:Key"];
...
// Subscribe to the status events.
listener.Connecting += (o, e) => { Console.WriteLine("Connecting"); };
listener.Offline += (o, e) => { Console.WriteLine("Offline"); };
listener.Online += (o, e) => { Console.WriteLine("Online"); };
var lmStudioClient = new LMStudioClient("unsloth/qwen3-30b-a3b-instruct-2507"); // The LM Studio model that will be used for orchestration.
var foundryLocalClient = new FoundryLocalClient("phi-4-mini"); // The Foundry Local model that will be initially loaded.
// Provide an HTTP request handler
listener.RequestHandler = async (context) =>
{
...
// Route the request to the appropriate client based on the request type.
// If the request type is "AdminTask", use the LMStudioClient to process the request.
// If the request type is "ChatCompletion", use the FoundryLocalClient to process the request.
if (requestData.Type == "AdminTask")
{
response = lmStudioClient.GetResponse(requestData.Text);
}
else if (requestData.Type == "ChatCompletion")
{
response = foundryLocalClient.GetResponse(requestData.Text);
}
context.Response.StatusCode = HttpStatusCode.OK;
context.Response.StatusDescription = "OK, Request processed";
using (var sw = new StreamWriter(context.Response.OutputStream))
{
await sw.WriteLineAsync(response);
}
// The context MUST be closed here
context.Response.Close();
};
...
// Close the listener after you exit the processing loop.
await listener.CloseAsync();
}
There are two LLM clients that are called by LocalRelayServer - FoundryLocalClient and LMStudioClient. FoundryLocalClient uses the Foundry Local SDK library as well as the C# OpenAI SDK to call the OpenAI compatible endpoint in Foundry Local:
public class FoundryLocalClient : LocalOpenAiClient
{
public FoundryLocalClient(string modelAlias) : base()
{
LocalOpenAiClient.manager = FoundryLocalManager.StartModelAsync(aliasOrModelId: modelAlias).Result;
ApiKeyCredential key = new ApiKeyCredential(manager.ApiKey);
var modelInfo = LocalOpenAiClient.manager.GetModelInfoAsync(aliasOrModelId: modelAlias).Result;
this.modelId = modelInfo?.ModelId;
LocalOpenAiClient.currentlyActiveModel = modelInfo;
client = new OpenAIClient(key, new OpenAIClientOptions
{
Endpoint = LocalOpenAiClient.manager.Endpoint
});
}
public override string GetResponse(string userMessage)
{
{
//Simple request response, since Foundry Local does not support tool calling.
if (client == null)
throw new InvalidOperationException("OpenAIClient is not initialized.");
if (modelId == null)
throw new InvalidOperationException("ModelId is not set.");
messages.Add(new UserChatMessage(userMessage));
var chatClient = client.GetChatClient(LocalOpenAiClient.currentlyActiveModel?.ModelId);
ChatCompletion completion = chatClient.CompleteChat(messages);
return completion.Content[0].Text;
}
}
}
LMStudioClient uses the C# OpenAI SDK (with an overridden inference endpoint) to call the LM Studio service. So no special LM Studio libraries are needed here, since the LM Studio service exposes a OpenAI compatible endpoint.
A number of LLM tools are defined in this client, which allows the LLM to invoke various functions on the local machine:
- Opening the task manager
- Listing the available models in the Foundry Local catalogue
- List the currently loaded models in Foundry Local
- Showing the GPU utilization on the local computer
- Loading models in Foundry Local
As an example, here is the definition for the tool that loads Foundry Local models:
private static readonly ChatTool loadModelTool = ChatTool.CreateFunctionTool(
functionName: nameof(LoadModel),
functionDescription: "Loads a model in Azure Foundry Local.",
functionParameters: BinaryData.FromString(
@"{
""type"": ""object"",
""properties"": {
""modelAlias"": {
""type"": ""string"",
""description"": ""The alias of the model to be loaded.""
}
},
""required"": [ ""modelAlias"" ]
}"
)
);
private static string LoadModel(string modelAlias)
{
try
{
FoundryLocalClient.currentlyActiveModel = LocalOpenAiClient.manager.LoadModelAsync(modelAlias).Result;
return "The model " + modelAlias + " has been loaded and is now active.";
}
catch (Exception ex)
{
return $"Failed to load model: {ex.Message}";
}
}
This way of defining tools is very verbose and is the result of me not using any orchestration framework - for example Microsoft Agent Framework - and instead using the “bare metal” OpenAI SDK.
All in all, this is fairly simple to setup but pretty powerful. There are quite a few scenarios where running models locally can be a good idea - for example data privacy and security when working with sensitive information, cost optimization for high-volume workloads, reduced latency for real-time applications, or offline capability when internet connectivity is limited or unreliable.
Disclaimer: This is a proof-of-concept for demonstration purposes only. Never expose local infrastructure to LLMs without proper security controls and threat modeling.
That being said, try it out for yourself - all code can be found in this repo. Happy hacking!
Here is a video that shows how it looks when everything is running: